
Помните что я писал в феврале 2019 года на тему сильных и слабых сторон iScala? Тогда я говорил, что сильные или слабые стороны могут быть только в сравнении с чем-то другим, с какой-то другой системой. Возможно, сейчас это покажется смешным, так как «другая система» победила, но победила вопреки, несмотря на то, что является убогой в некоторых очень важных вопросах, и я хочу на них сейчас остановиться. Как выяснилось в процессе перехода моего клиента (связанного с уходом Эпикора из России) на работу в «другую систему», название которой состоит из одной цифры и одной буквы (не хочу произносить это вслух), её база данных абсолютно непригодна для того, чтобы строить отчёты, подобные тем, что имелись в iScala на сервере отчётов MS SQL Server Reporting Services. В чём вопрос? А дело в том, что «другая система» использует базу данных как табличную помойку, хотя звучит это довольно бравурно «Динамические структуры данных». Если посмотреть на список таблиц, вы не увидите стройной системы, как в БД iScala, вы увидите примерно следующее (картинки получены из тестовой БД):

В разных таблицах с одинаковым префиксом разные наборы полей, а если заглянуть наугад в какую-то таблицу, то вместо собственно данных, мы увидим какие-то ссылки:
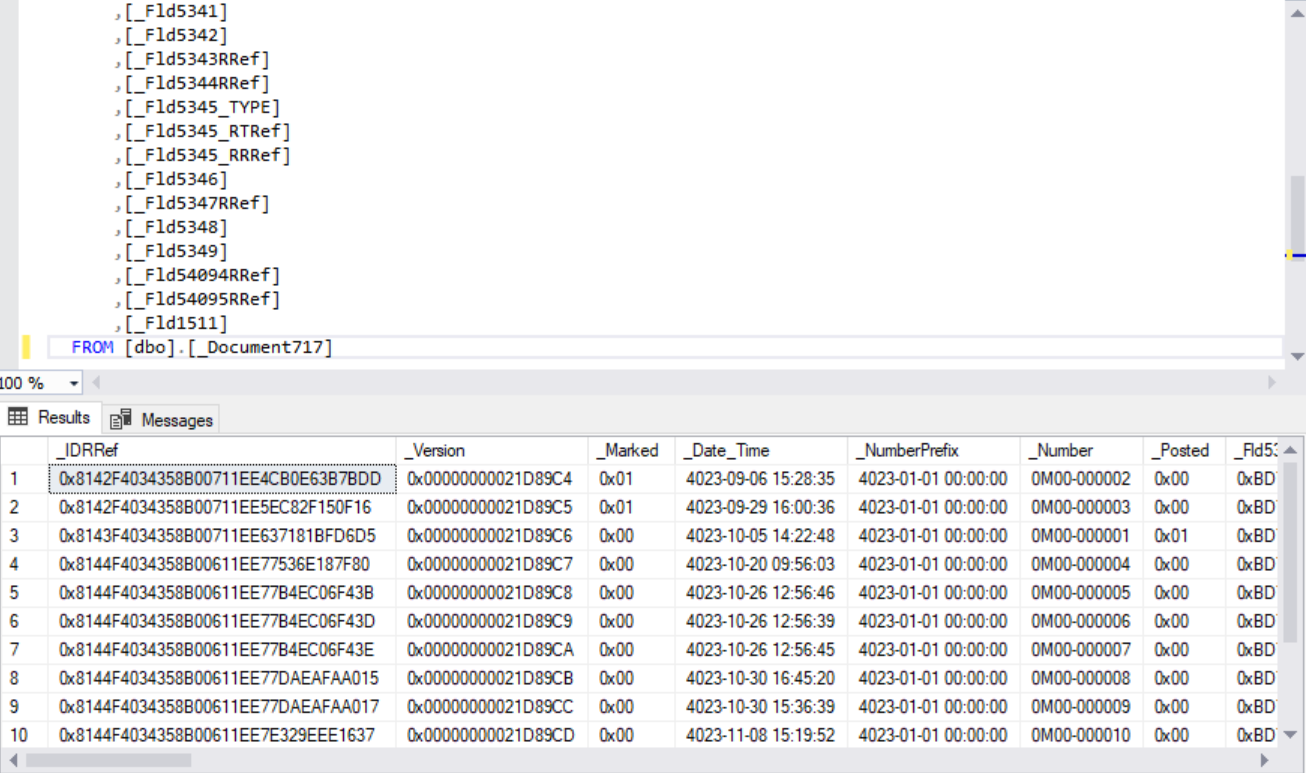
В чём суть такого подхода? Давайте поищем ответ в интернете (не важно, какую конкретно страницу я буду цитировать, они все друг друга дублируют):
Динамические структуры данных – это способ организации и хранения информации в программировании, который позволяет эффективно добавлять, удалять и изменять элементы данных в процессе выполнения программы. Они отличаются от статических структур данных тем, что их размер и форма могут изменяться в зависимости от потребностей программы.
Динамические структуры данных предоставляют гибкость и эффективность при работе с данными, так как позволяют динамически выделять и освобождать память для хранения элементов данных. Это позволяет программе адаптироваться к изменяющимся условиям и оптимизировать использование ресурсов.
Примерами динамических структур данных являются списки, стеки, очереди, деревья и графы. Каждая из этих структур имеет свои особенности и применяется в различных ситуациях в программировании
«списки, стеки, очереди, деревья и графы» — типичный тупой программистский подход, когда вместо того, чтобы послать запрос и получить ограниченный набор данных, программа получает массив целиком и обрабатывает его внутри себя. Я, конечно, не знаю, как там это всё организовано в «другой системе», возможно вышеприведённая цитата не вполне подходит, но вижу, что её БД, в отличие от БД iScala, абсолютно не отчётопригодна. Все отчёты получаются внутри системы, получить требуемое средствами SQL Server’а не представляется сколько-нибудь разумным.
Сейчас клиент обсуждает вопрос какой-то репликации, когда из «другой системы» её внутренними процедурами выгружалась бы информация в обычном табличном виде. Очень надеюсь, что компания, осуществляющая внедрение, справится с этой задачей.
И да, это моё личное мнение, я не утверждаю, что оно единственно правильное и никому его не навязываю 🙂
Продолжение темы: «В поисках идеальной ERP системы 2.01»…


